一直以來對於寫這種文章我是有疑慮的
預測證券市場走勢是一項非常有誘惑力的事情,但是一旦稍有不慎或是過度相信程式,很有可能在黑天鵝事件來臨時,粉身碎骨。
我個人認為,與其努力的在每日獲利上能夠跑贏大盤,不如好好享受在運用程式預測的練習中,學習資料視覺化,程式設計,模型訓練這些領域,說不定在這個領域所學應用在工作上提升的收入,會比投資炒股多很多XD
本篇文章會讓大家簡單地做出像下方的股價預測圖,以及調整參數,預測未來的股價

本文的示範資料集與程式碼我把他打包好放在雲端了
使用方式與雲端連結請點下方
https://hn28082251.blogspot.com/2019/05/python-stocker-data-code.html
本次環境使用anaconda裡面的jupyter
不會操作的請先參考這篇
https://hn28082251.blogspot.com/2019/02/python-mac-os-anaconda.html
我們先來建立個過去股價的資料
這裡用的方法是用google試算表抓資料
詳細方法請參考以下教學
https://hn28082251.blogspot.com/2019/04/google-spreadsheets-stock.html
https://hn28082251.blogspot.com/2018/12/google-k.html
我們在這裡用我在台股的唯一持股玉山金為例
程式碼先幫大家寫好
可以直接複製
={ArrayFormula(text({"Date";int(query(query(googlefinance("2884","ALL","1/1/2018",TODAY(),"daily" ) ,"Select Col1",1),"offset 1",0))},"YYYY-MM-DD")),query(googlefinance("2884","ALL","1/1/2018",TODAY(),"daily" ) ,"Select Col4,Col2,Col5,Col3",1)}
以上是從2018年開始抓
詳細的抓取步驟可以參照下方這篇
https://hn28082251.blogspot.com/2019/04/python-stocker.html
再來說說我們要用的stocker套件
如果大家有照著下方的教學打開程式碼後
https://hn28082251.blogspot.com/2019/05/python-stocker-data-code.html
可以開始按上方run那個鍵
導入Stocker:
from stocker import Stocker

這部分可能有些第一次使用的人會出現很多錯誤
通常是因為缺少相關套件
所需套件如下
quandl==3.3.0
matplotlib==2.1.1
numpy==1.14.0
fbprophet==0.2.1
pystan==2.17.0.0
pandas==0.22.0
pytrends==4.3.0
通常anaconda會預載matplotlib、numpy、pandas、pytrends
所以缺少的套件quandl、pystan、fbprophet就需要手動安裝
mac的使用者直接進終端機,然後依序輸入下方程式並執行
pip install quandl
pip install pystan
pip install fbprophet
windows的使用者則去開始功能表打開anaconda資料夾
找到裡面一個長得像命令提示字元,名稱叫做Anaconda Prompt的程式執行,然後依序輸入下方程式並執行
pip install quandl
conda install pystan
conda install -c conda-forge fbprophet
如果以上執行成功代表我們有抓到package了
再來把股價資料讀取進來
import pandas as pd
### 讀入series
df = pd.read_csv('price2884.csv', index_col='date', parse_dates=['date'])
price = df.squeeze()
price.head()
確定資料格式沒有問題
再來讀取價格資料放進一個變數中
from stocker import Stocker
esun = Stocker(price)
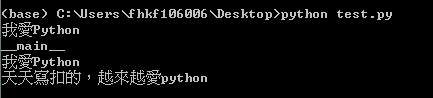
確定時間沒問題後,就可以開始初步預測了
預測的程式如下
model, model_data = esun.create_prophet_model(days=10)
#days代表要預測幾天後的股價
由此可見這裡預測的十天後(6/7)玉山金的股價為26.62元
是不是很簡單呢?
預測結果的綠線包含了相對應的信賴區間,這代表在模型預測的不確定性。在這種情況下,如果將信賴區間寬度設置為80%,這意味著我們預計這個範圍將包含實際值的可能性為80%。信賴區間將隨著時間推移會越來越大,這是因為隨著預測時間距離現有數據的時間越來越遠,預測值將面臨更多的不確定性,就像預測天氣一樣。
教的是如何使用Changepoint Prior,來進行模型調整
官方說明如後
Changepoints represent where a time series goes from increasing to decreasing or from increasing slowly to increasingly rapidly (or vice versa). They occur at the places with the greatest change in the rate of the time series. The changepoint prior scale represents the amount of emphasis given to the changepoints in the model. This is used to control overfitting vs. underfitting (also known as the bias vs. variance tradeoff).
簡單的來說就是控制overfitting(過擬和) 跟 underfitting(欠擬和)
overfitting(過擬和)是指,使用過多參數,以致太適應資料,太適應資料可能會在未來預測的時候失準
underfitting(欠擬和)是使用太少參數,以致於不適應資料
在上方教學中,我們已經學會如何快速建模,不過我們要來評估模型的預測效果如何,就用下方的程式碼來用過去資料來看看三個月前開始預測效果如何
esun.evaluate_prediction(start_date='2019-02-04', end_date='2019-05-28')
執行後如下
紅線之前代表訓練集的數據,紅線後代表開始預測,可以看得出來,並不是很理想!!!
但不要因此放棄,因為一開始全部都使用默認的參數,所以我們要開始去調整我們的模型,
趨勢變化過度擬合(靈活性太大)或不足(靈活性不夠),我們可以使用輸入參數調整稀疏之前的強度changepoint_prior_scale。默認情況下,此參數預設為0.05。增加它將使趨勢更加靈活
我們輸入下方這行程式碼並且執行
esun.changepoint_prior_analysis(changepoint_priors=[0.001, 0.05, 0.1, 0.2])
可以得到下方這張圖
可以看到在不同的changepoint_priors下,擬合的狀況也不太相同
接下來我們在更詳細的比較不同的changepoint_priors下,一些其他的參考值
程式碼如下
esun.changepoint_prior_validation(start_date='2018-01-04', end_date='2019-01-03', changepoint_priors=[0.001, 0.05, 0.1,0.15, 0.2, 0.25,0.4, 0.5, 0.6])
基於不同changepoint_priors下,訓練和測試準確性曲線和不確定性曲線
大致上可以看得出來,在changepoint_priors=0.1的時候效果較好
於是我們就把changepoint_prior_scale設成0.1吧!請加入下方的程式碼並執行
esun.changepoint_prior_scale = 0.1
然後再去看我們的模型
一樣用下方的程式碼
esun.evaluate_prediction(start_date='2019-02-04', end_date='2019-05-28')
可以發現預測的走勢比較貼近我們的現實數據了,這顯示了模型優化的重要性。使用默認值可以初步預測,但是我們需要調整模型的設定,來讓模型效果更好。
下一篇會講講比較參考模型進行買進賣出或者是單純持有之間的差異,以及用修正後的模型進行預測
本文章並沒有推薦任何投資標的,單純是個人的一些觀察與見解,為作者自行查看相關資料後整理而成,資料之正確性以各官方公告為主,任何人觀看本文之後,而有投資該股票基金或ETF之行為,自行對所有後果負責。
歡迎分享轉載文章,願每一個人都能夠衣食無虞。
我將思想傳授他人,他人之所得,亦無損於我之所有;猶如一人以我的燭火點燭,光亮與他同在,我卻不因此身處黑暗。湯瑪斯‧傑弗遜(Thomas Jefferson)