簡單介紹隨機森林(Random Forest)顧名思義,是用隨機的方式建立一個森林。
隨機森林的用途,主要是處理分類與回歸問題,並且在沒有提高運算量的情況下提高了精確度。
優點如下
1.有效的處理缺失值,並且填補缺失值,即使有大量數據缺失仍然可以維持高精確度
2.有效的處理少量資料。
3.對於數據挖掘、檢測離群點和數據可視化非常有用。
缺點
1.在某些雜訊較大的分類和回歸問題上會過擬合(overfitting)
簡單的說,隨機森林可以視為決策樹(Decision Tree)的延伸
什麼是決策樹呢?我們可以想想我們的人生,每做一個決策,就會出現不同的結果,種種不同的決策下,長成了現在的我們,這個分叉出去的人生,就像一棵樹倒過來一樣,用下面這個圖比較明瞭。
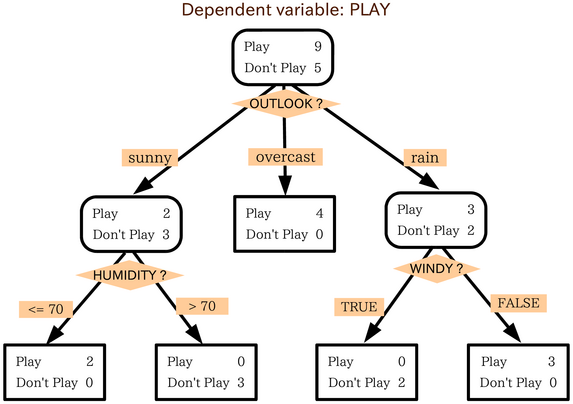 |
| 決策樹-取自維基百科 |
以下用幾張圖來讓大家簡單明瞭


一般很多的決策樹算法都一個重要的步驟 – 剪枝,但是隨機森林不會。(剪枝的意義是:防止決策樹生成過於龐大的子葉,避免實驗預測結果過擬合,在實際生產中效果很差)
隨機森林裡面的每棵樹的產生的過程中,都已經考慮了避免共線性,避免過擬合,剩下的每棵樹需要做的就是盡可能的在自己所對應的數據(特徵)集情況下盡可能的做到最好的預測結果。
用隨機森林對一個新的對象進行分類判別時,隨機森林中的每一棵樹都會給出自己的分類選擇,並由此進行「投票」,森林整體的輸出結果將會是票數最多的分類選項;而在回歸問題中,隨機森林的輸出將會是所有決策樹輸出的平均值。
以上,希望可以幫助大家快速了解隨機森林及用途,如果有寫得不夠詳細的部分,也歡迎留言討論,最後~希望可以讓長官深入淺出快速理解並支持(?



沒有留言:
張貼留言