後來隨著硬體逐漸的發展,直到2012年波茲曼機的發明人Hinton發明了對比分歧法(Contrast Divergence),在分類、特徵抽取等方面頗有斬獲,還可以和多層感知器疊合,創造出了深度神經網路,而後來深度神經網路又加入了Convolutional(中文譯作卷積)運算,成為了卷積神經網路,在影像辨識上非常有效,接著開始推展到人工智慧的各個領域,也就跟上了這一波機器學習與深度學習的熱潮(之後再來開一篇講人工智慧的興衰到再次崛起)。
我知道上面說了一堆專有名詞大家已經頭昏眼花了,接下來簡單的說説類神經網路吧

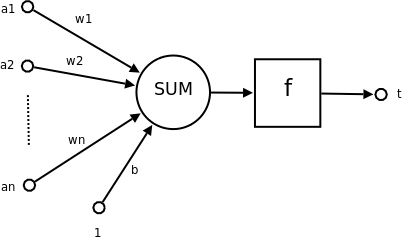 |
類神經網路 from wiki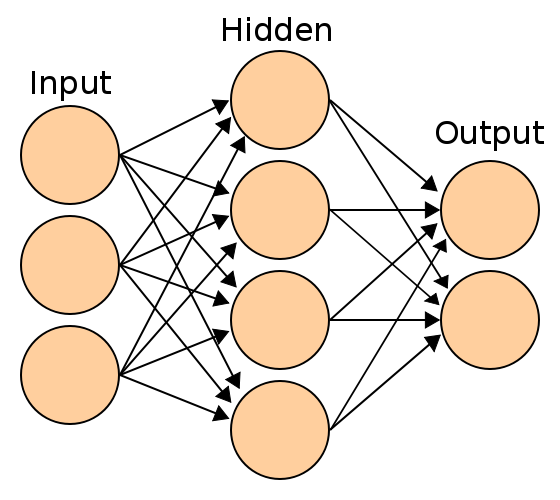 |
簡單介紹各層
輸入層(Input layer):透過許多神經元(Neuron)接受大量資訊。
輸出層(Output layer):資訊在神經元鏈接中傳輸、分析,形成預測結果。
隱藏層(Hidden layer):模擬複雜的非線性關係,好比人類的神經突觸連結越多,就會越聰明。但是過多的話會有過度學習的狀況,所以也不是越多越好。
類神經網路有以下幾個重點
1.每個神經元都與下一層所有神經元連接
2.屬於同一層的神經元之間沒有任何連接
3.有幾層以及每一層有幾個神經元由待解決的問題決定
接下來順帶簡單介紹一下機器學習的學習模式
監督式學習(Supervised learning):在訓練的過程中告訴機器答案、也就是「有標籤Label」的資料,比如給機器各看了 1000 張貓和豿的照片後、詢問機器新的一張照片中是貓還是豿。
非監督式學習(Unsupervised learning):訓練資料沒有標準答案、不需要事先輸入標籤,所以機器在學習的過程中並不知道其分類結果是否正確。訓練時僅須對機器提供輸入範例,機器會自動從這些範例中找出潛在的規則。
增強學習(Reinforcement learning):或稱作強化式學習,透過觀察環境而行動,並會隨時根據新進資料修正、以獲得最大成果,特徵是訓練必須要有正負回報(positive/negative reward)。
另外的半監督式學習(Semi supervised learning),可視為監督式學習與非監督式學習的混合版,資料中少部分有標記,大部分沒有標記。
以上希望可以幫助大家快速了解類神經網路以及機器學習的模式,如果有寫得不夠詳細的部分,也歡迎留言討論。